Single-File Stress Benchmarks
Single-file benchmarks focus on large structures and parser-heavy cases that are hidden by directory-level averages. The pinned current benchmark suite uses eight protein-only PDB inputs, 100 sphere points, and 10 threads for the headline results.
Runtime and memory
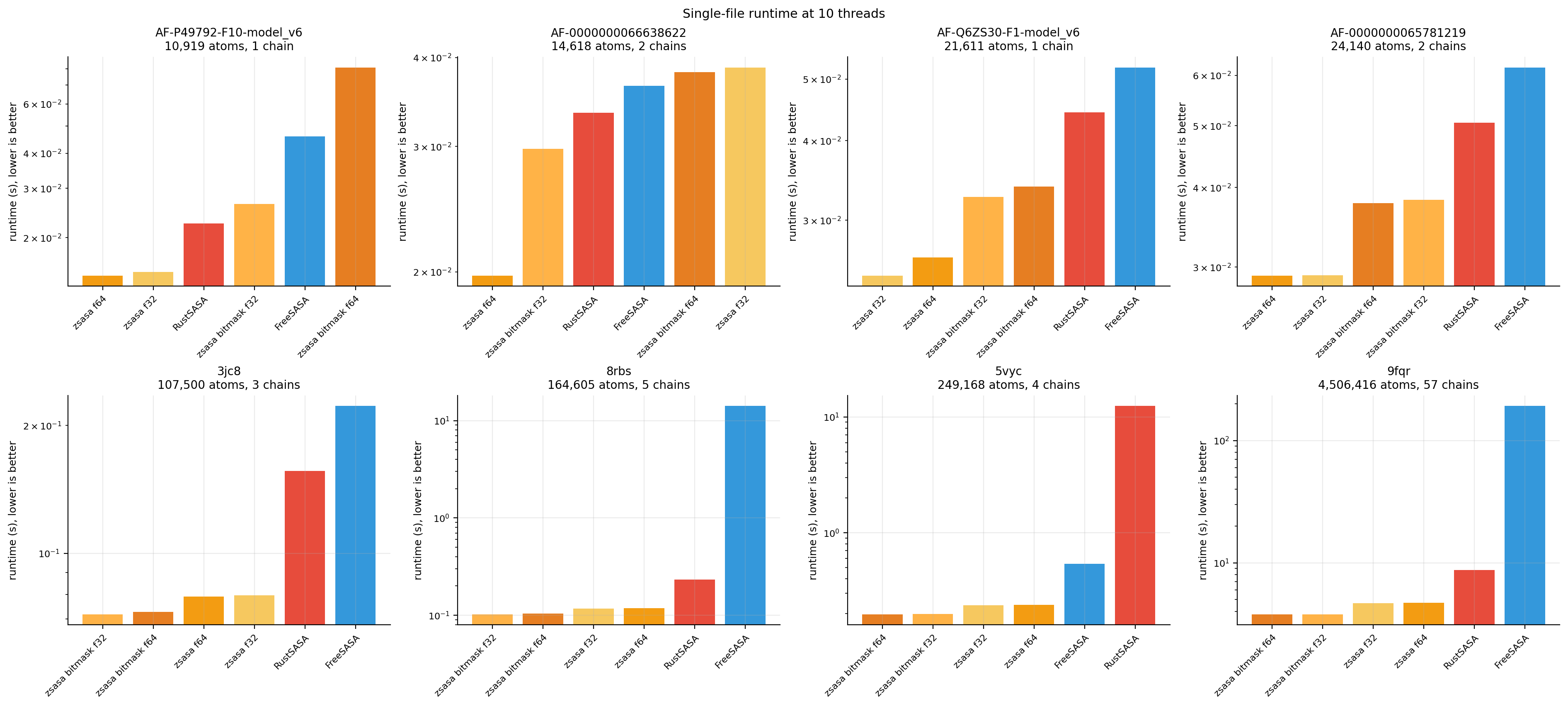
Figure 1. Single-file runtime bars. Absolute wall-clock time across the eight curated structures at 10 threads.
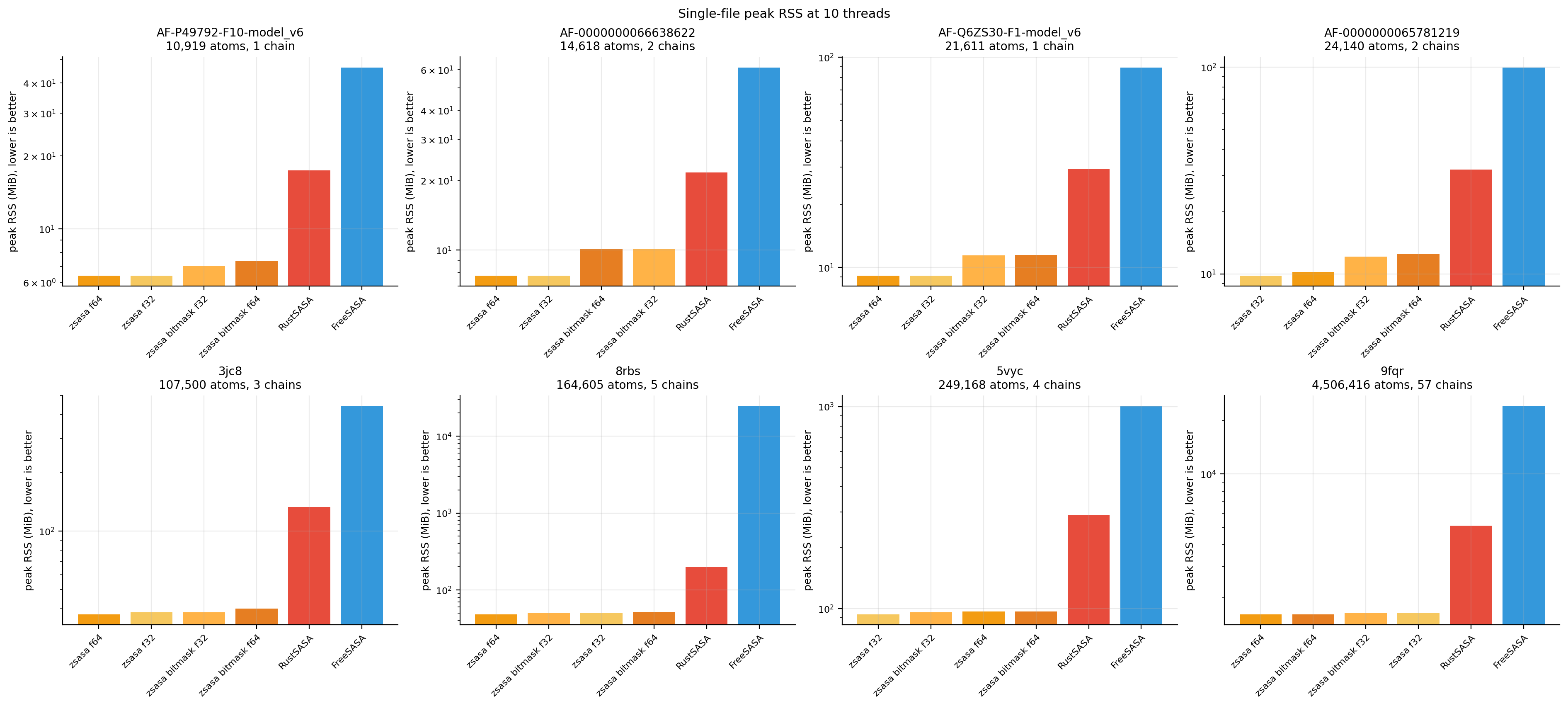
Figure 2. Single-file peak RSS bars. Peak memory remains lower for zsasa across the large-structure and parser-stress cases.
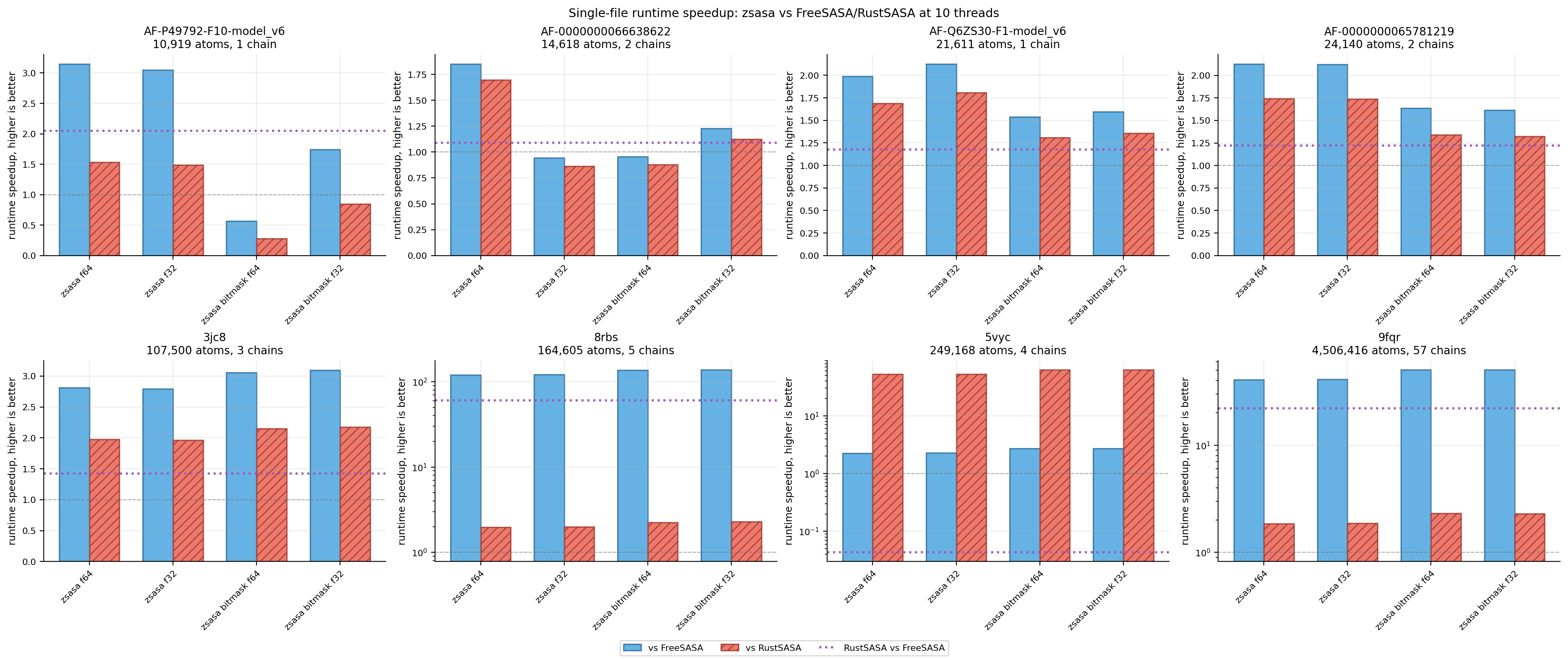
Figure 3. Single-file runtime speedup ratios. The n× view highlights parser and very-large-structure stress cases.
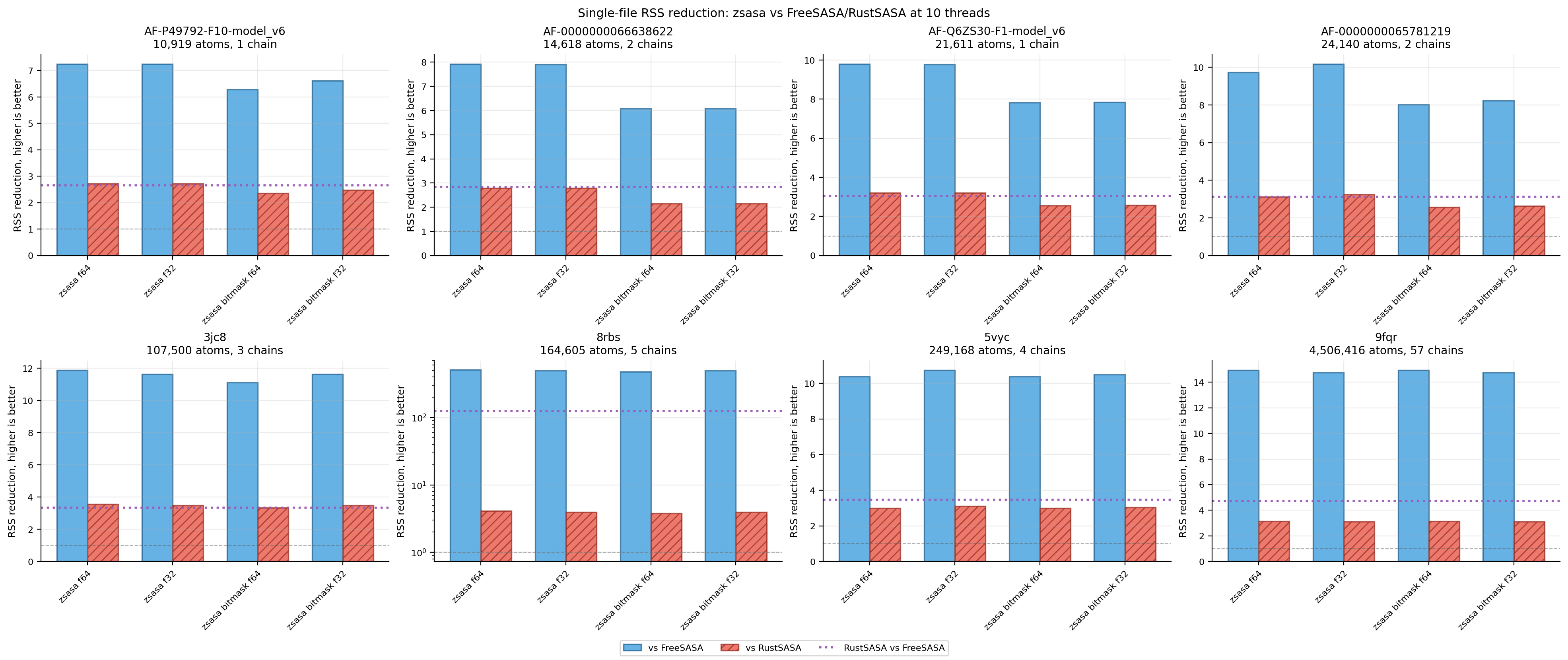
Figure 4. Single-file RSS reduction ratios. Memory ratios are shown alongside absolute RSS bars.
Selected 10-thread results:
| Structure | Mode | Runtime | RSS | Speedup vs FreeSASA | Speedup vs RustSASA |
|---|---|---|---|---|---|
| AF-Q6ZS30-F1, 21,611 atoms | zsasa f64 | 0.026 s | 9.1 MiB | 1.99× | 1.69× |
| AF-Q6ZS30-F1, 21,611 atoms | zsasa bitmask f64 | 0.034 s | 11.4 MiB | 1.54× | 1.31× |
| 5vyc, 249,168 atoms | zsasa f64 | 0.238 s | 96.8 MiB | 2.26× | 52.3× |
| 5vyc, 249,168 atoms | zsasa bitmask f64 | 0.197 s | 96.8 MiB | 2.73× | 63.0× |
| 8rbs, 164,605 atoms | zsasa f64 | 0.118 s | 48.1 MiB | 119.7× | 1.97× |
| 8rbs, 164,605 atoms | zsasa bitmask f64 | 0.104 s | 51.9 MiB | 136.5× | 2.25× |
| 9fqr, 4,506,416 atoms | zsasa f64 | 4.696 s | 1,615 MiB | 40.9× | 1.86× |
| 9fqr, 4,506,416 atoms | zsasa bitmask f64 | 3.788 s | 1,616 MiB | 50.6× | 2.30× |
Dataset
Inputs were normalized to protein-only PDB files for fair comparator runs: hydrogens, alternate conformations, ligands, waters, and non-L-peptide chains were removed; atom and residue identifiers were wrapped into PDB field limits when needed.
| Structure | Role | Atoms | Chains | Note |
|---|---|---|---|---|
| AF-P49792-F10 | single-medium | 10,919 | 1 | AFDB single-chain case |
| AF-Q6ZS30-F1 | single-large | 21,611 | 1 | AFDB large single-chain case |
| AF-0000000066638622 | multi-medium | 14,618 | 2 | AFDB-derived two-chain case |
| AF-0000000065781219 | multi-large | 24,140 | 2 | AFDB-derived two-chain case |
| 3jc8 | 100k-atom | 107,500 | 3 | PDB assembly |
| 5vyc | RustSASA stress | 249,168 | 4 | Parser-heavy RustSASA case |
| 8rbs | FreeSASA stress | 164,605 | 5 | PDB coordinate-overflow parser case |
| 9fqr | maximum-size | 4,506,416 | 57 | Largest assembly in this subset |
Lahuta is excluded from this suite because the benchmarked SASA command targets AlphaFold-style chain-A inputs and cannot process this mixed multi-chain subset.
Parse versus SASA timing
zsasa records component timings with its native --timing path. The benchmark harness also used timing-enabled comparator builds so parse and kernel effects could be separated.
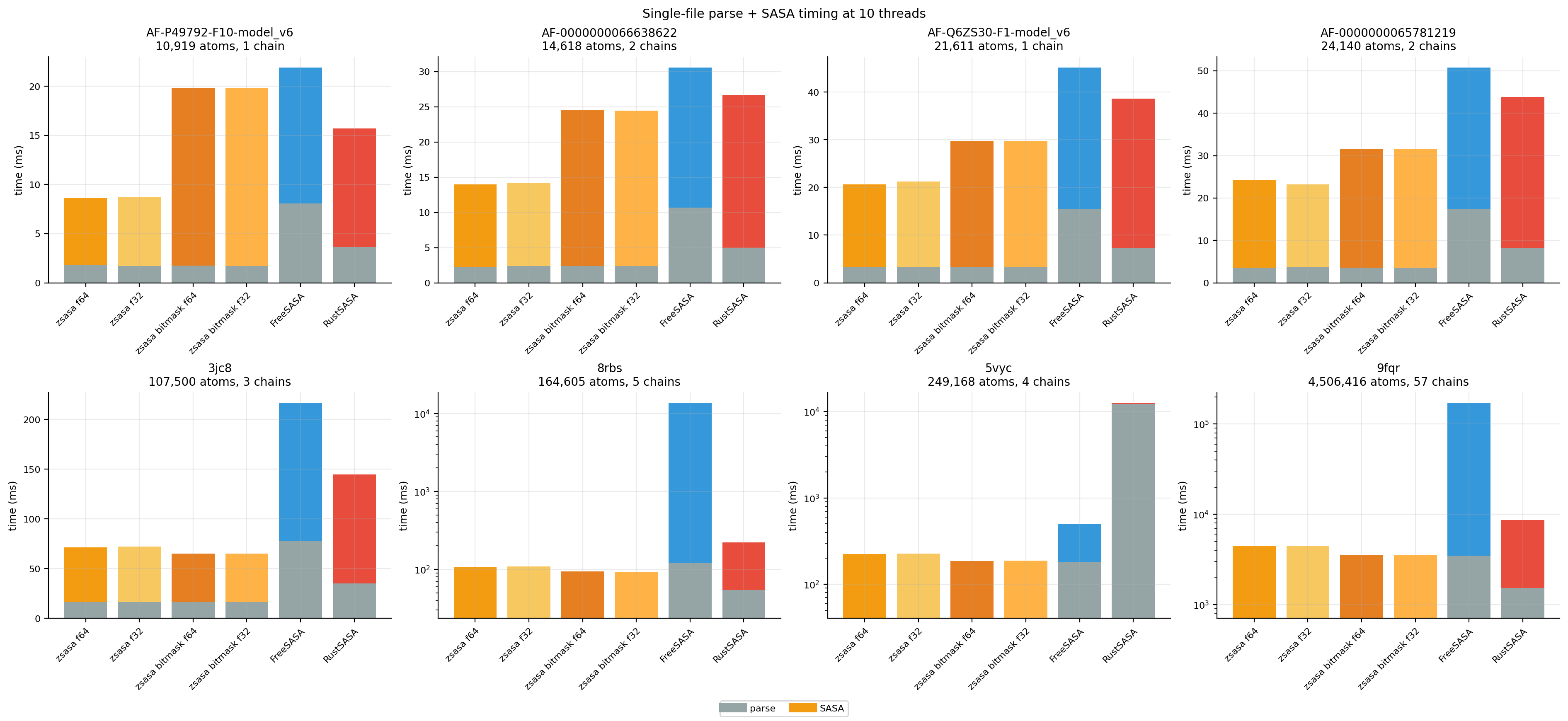
Figure 5. Parse time versus SASA-kernel time. On the largest assembly, zsasa f64 spent about 708 ms parsing and 3,754 ms in SASA calculation; bitmask reduced the SASA component to about 2,861 ms.
Selected component timings:
| Structure | Tool/mode | Parse | SASA kernel | Wall runtime |
|---|---|---|---|---|
| 5vyc | zsasa f64 | 40.4 ms | 184.1 ms | 0.238 s |
| 5vyc | RustSASA | 12,204.5 ms | 349.9 ms | 12.430 s |
| 8rbs | zsasa f64 | 23.5 ms | 84.3 ms | 0.118 s |
| 8rbs | FreeSASA | 119.4 ms | 13,467.4 ms | 14.150 s |
| 9fqr | zsasa f64 | 707.8 ms | 3,753.7 ms | 4.696 s |
| 9fqr | FreeSASA | 3,486.1 ms | 167,332.8 ms | 191.876 s |
| 9fqr | RustSASA | 1,526.6 ms | 7,100.0 ms | 8.731 s |
Thread scaling
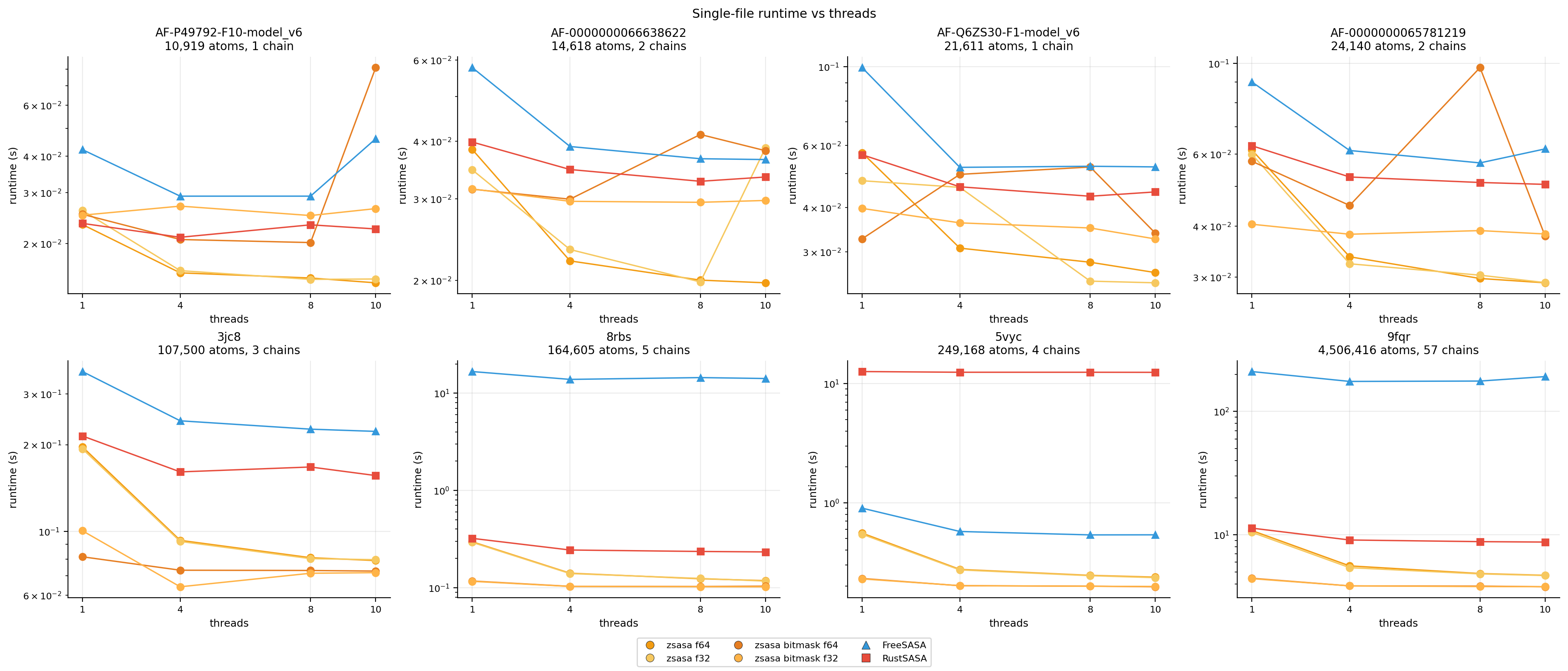
Figure 6. Runtime versus thread count across the curated single-file subset. Thread scaling depends on structure size and parser behavior; the largest structures benefit most from parallel SASA calculation.
Caveats
- The 8rbs FreeSASA result primarily exposes PDB fixed-width coordinate overflow and coordinate misreading rather than ordinary FreeSASA kernel scaling.
- The 5vyc RustSASA result is dominated by parser time.
zsasaaccepted the raw large-structure inputs directly, but all tools were timed on the same normalized PDB files for fairness.
Evidence source
The values above are exported from zsasa-benchmarks/results/tables/single_file_t10_summary.csv and single_file_thread_scaling.csv.