MD Trajectory Benchmarks
Trajectory benchmarks measure frame-wise SASA calculation under streaming, low-memory conditions. The current pinned throughput suite uses 100 sphere points, 10 threads, stride 1, the NACCESS classifier, and explicit hydrogens.
Throughput summary
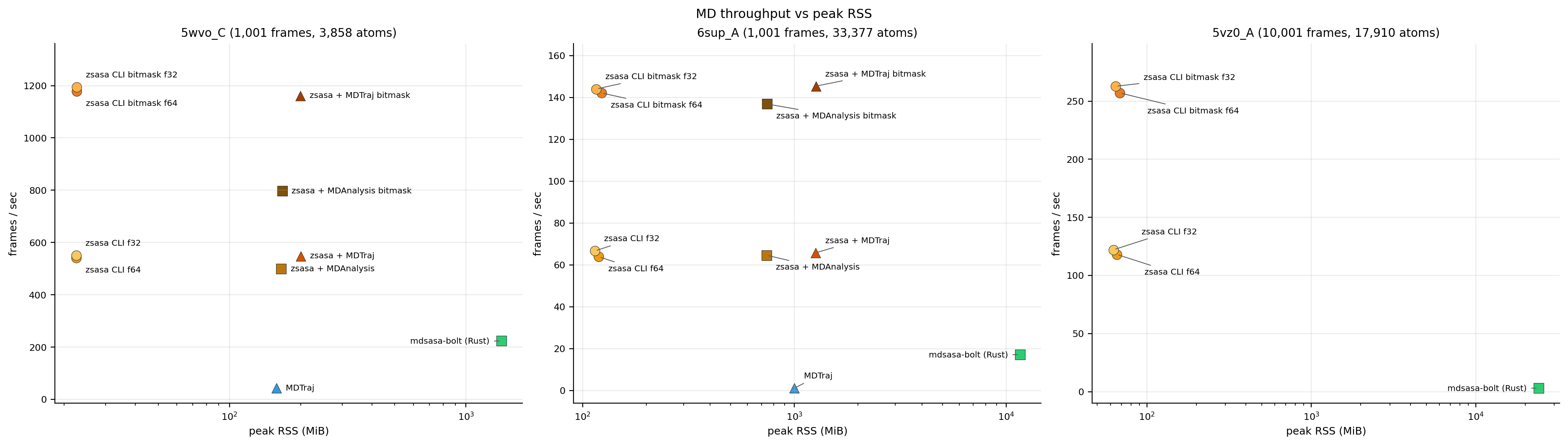
Figure 1. MD throughput versus peak RSS. The zsasa CLI paths occupy the high-throughput, low-memory region across the three workloads.
Headline values:
| Dataset | Best zsasa mode | Runtime | Frames/s | RSS | Speedup |
|---|---|---|---|---|---|
| 5wvo_C | CLI bitmask f32 | 0.839 s | 1,194 | 22.6 MiB | 27.8× vs MDTraj |
| 6sup_A | CLI bitmask f32 | 6.949 s | 144 | 115.9 MiB | 132× vs MDTraj |
| 5vz0_A | CLI bitmask f32 | 38.056 s | 263 | 64.6 MiB | 86.5× vs mdsasa-bolt |
Per-dataset comparison
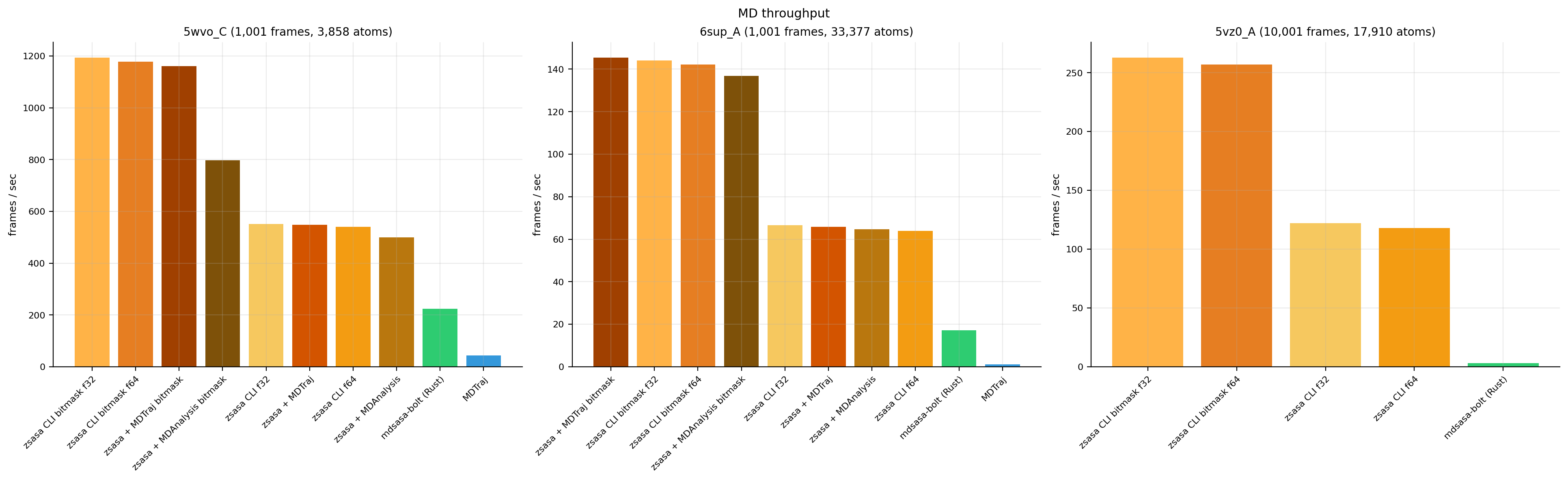
Figure 2. Frames per second across trajectory workloads. zsasa CLI exact and bitmask modes are the fastest low-memory paths in the benchmarked workloads.
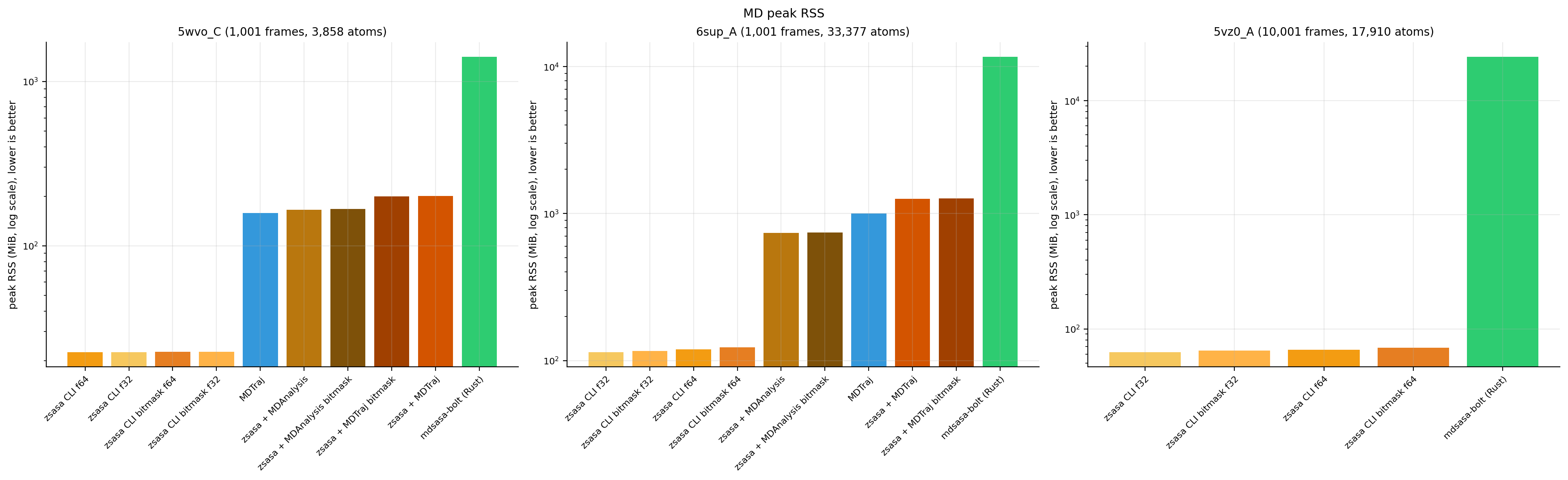
Figure 3. Peak RSS across trajectory workloads. The absolute-memory bars show why streaming trajectory processing matters for large or long trajectories.
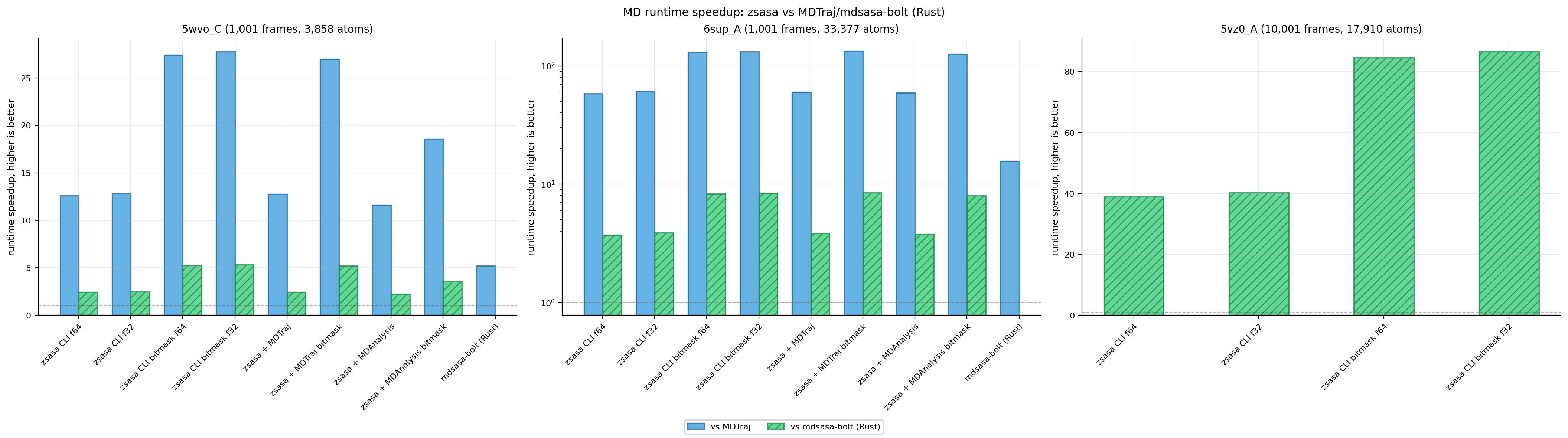
Figure 4. MD runtime speedup ratios. The n× speedup view is retained for direct comparator comparisons.
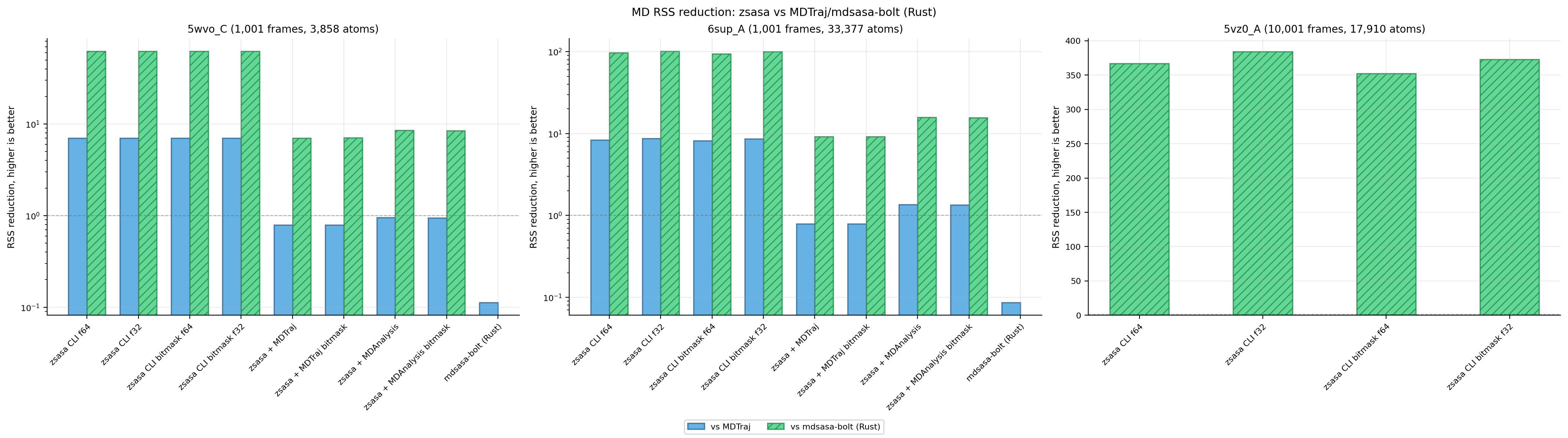
Figure 5. MD RSS reduction ratios. This view shows the memory advantage of streaming trajectory processing.
Per-dataset values:
| Dataset | Tool/mode | Runtime | Frames/s | RSS | Notes |
|---|---|---|---|---|---|
| 5wvo_C | zsasa CLI f64 | 1.850 s | 541 | 22.5 MiB | 12.6× faster than MDTraj |
| 5wvo_C | zsasa CLI bitmask f32 | 0.839 s | 1,194 | 22.6 MiB | 27.8× faster than MDTraj |
| 5wvo_C | MDTraj | 23.285 s | 43.0 | 158.0 MiB | Native reference comparator |
| 5wvo_C | mdsasa-bolt (Rust) | 4.477 s | 223.6 | 1,409 MiB | Higher memory via MDAnalysis front-end |
| 6sup_A | zsasa CLI f64 | 15.671 s | 63.9 | 119.2 MiB | 58.6× faster than MDTraj |
| 6sup_A | zsasa CLI bitmask f32 | 6.949 s | 144 | 115.9 MiB | 132× faster than MDTraj |
| 6sup_A | MDTraj | 917.892 s | 1.1 | 1,001 MiB | Native reference comparator |
| 6sup_A | mdsasa-bolt (Rust) | 58.596 s | 17.1 | 11,621 MiB | High peak RSS |
| 5vz0_A | zsasa CLI f64 | 84.670 s | 118 | 65.6 MiB | 38.9× faster than mdsasa-bolt |
| 5vz0_A | zsasa CLI bitmask f32 | 38.056 s | 263 | 64.6 MiB | 86.5× faster than mdsasa-bolt |
| 5vz0_A | mdsasa-bolt (Rust) | 3,293.112 s | 3.0 | 24,082 MiB | MDTraj not run for this long trajectory |
Workloads
| Dataset | Frames | Atoms | Source | Use |
|---|---|---|---|---|
| 5wvo_C | 1,001 | 3,858 | ATLAS | validation and throughput |
| 6sup_A | 1,001 | 33,377 | ATLAS | large-system throughput |
| 5vz0_A | 10,001 | 17,910 | ATLAS | long-trajectory throughput |
Memory interpretation
zsasa streams trajectory frames and keeps memory close to the current-frame working set. In contrast, the mdsasa-bolt path uses an MDAnalysis front-end that materializes atom data for every frame before the Rust SASA core runs, so its peak memory grows with trajectory length.
Validation pointer
Trajectory validation against MDTraj is covered in SASA Validation. In short, agreement improves with point count: the zsasa+MDTraj path reaches R² = 0.9938 at 500 points and R² = 0.9983 at 1,000 points on 5wvo_C.
Evidence source
The values above are exported from zsasa-benchmarks/results/tables/md_summary.csv and validation_pairwise_summary.csv.